이 글은 우아한 기술블로그에 기재된 HikariCP Dead lock에서 벗어나기 (이론편) 을 기반으로 작성된 글입니다.
HikariCP Dead lock에서 벗어나기 (이론편) | 우아한형제들 기술블로그
{{item.name}} 안녕하세요! 공통시스템개발팀에서 메세지 플랫폼 개발을 하고 있는 이재훈입니다. 메세지 플랫폼 운영 장애를 바탕으로 HikariCP에서 Dead lock이 발생할 수 있는 case와 Dead lock을 회피할
techblog.woowahan.com
개요
Application단의 Thread 개수, 하나의 Task에서 발생하는 총 Connection의 수, 그리고 HikariCP Connection pool의 크기에는 정말 중요한 연관관계가 존재합니다. 바로 데드락 발생의 유무인데요!
때문에, Tomcat이나 HikariCP 성능 튜닝을 진행할 때는 이에 대한 기반 지식을 알고 튜닝을 진행해야만, 큰 장애를 미연에 방지할 수 있습니다.
데드락 상황을 알아보기 이전에, HikariCP에서 Connection을 가져오는 과정을 살펴보자면 아래의 Flow chart와 같습니다.

간략하게 정리하자면, Connection 요청 시 Connection Pool(이하 CP) 에서 idle 상태인 Connection을 찾아 반납해주되, 사용 가능한 Connection이 없는 경우에는 handOffQueue에서 대기합니다. 이때 설정된 시간안에 Connection을 얻지 못한다면, Connction timeout이 발생합니다.
HikariCP 데드락 발생 상황
이 글의 메인 주제입니다.
Application Thread 개수, 하나의 Task에서 필요한 총 Connection의 수, 그리고 HikariCP의 최대 CP 크기가 적절히 설정되지 못한다면, HikariCP 데드락이 발생하게 되는데요.
언제, 그리고 왜 발생하는지를 깊이 있게 살펴보겠습니다.
데드락, 언제 발생하는가?
개념은 생각보다 어렵지 않습니다. 하나의 Task에서 필요한 총 Connection의 수보다, CP에서 idle 상태로 대기중인 Connection의 수가 더 부족한 상황일 때, 두 개 이상의 Thread가 서로 Connection을 얻으려고 하면서 Race Condition이 발생합니다. 그리고 이는 곧 데드락을 의미하죠.
특히 이 데드락 시나리오는, 부하를 받는 상황에서 발생할 확률이 높습니다.
데드락, 왜 발생하는가?
언제 발생하는지는 알겠는데, 조금 더 구체적으로 ‘대체 왜?’ 에 대한 부분을 다뤄보고자 합니다.
일단 이해를 돕기 위해, 데드락이 발생하는 간단한 예제 코드를 가져왔습니다.
@Service
public class MemberService {
private final MemberAnotherService memberAnotherService;
private final MemberRepository memberRepository;
public MemberService(final MemberAnotherService memberAnotherService,
final MemberRepository memberRepository) {
this.memberAnotherService = memberAnotherService;
this.memberRepository = memberRepository;
}
@Transactional
public Long save() {
System.out.println("MemberService.save() 에서 Connection 1개 사용 예정...");
final Member member = new Member("kokodak");
final Member save = memberRepository.save(member);
memberAnotherService.anotherSave();
return save.getId();
}
}@Service
public class MemberAnotherService {
private final MemberRepository memberRepository;
public MemberAnotherService(final MemberRepository memberRepository) {
this.memberRepository = memberRepository;
}
@Transactional(propagation = Propagation.REQUIRES_NEW)
public void anotherSave() {
System.out.println("MemberAnotherService.anotherSave() 에서 Connection 1개 추가로 사용 예정...");
final Member member = new Member("kukuduk");
memberRepository.save(member);
}
}
상황에 대한 스펙은 아래와 같습니다.
MemberService.save()시나리오에서 필요한 Connection 수: 2개- HikariCP maximum pool size: 1개
위 상황에서, MemberService.save() 를 호출할 경우, 한 태스크에서 필요한 Connection의 수(2개)보다 CP에서 대기하는 Connection의 수(1개)가 더 적은 상황이 발생합니다. 따라서 해당 Thread에서는 Connection을 얻기 위해 계속 대기하게 되며, 결국 아래와 같은 Connection timeout 에러를 맞이하게 됩니다.
다만 위의 상황은 간단한 이해를 위한 예시이므로, 지금보다 조금 더 복잡한 상황을 가정해보겠습니다.
상황에 대한 스펙은 아래와 같습니다.
- 최대 Thread 개수: 5개
- HikariCP maximum pool size: 4개
- 한 Thread당 필요한 Connection의 수: 2개
- Thread가 전체적으로 일하고 있는 부하 상황
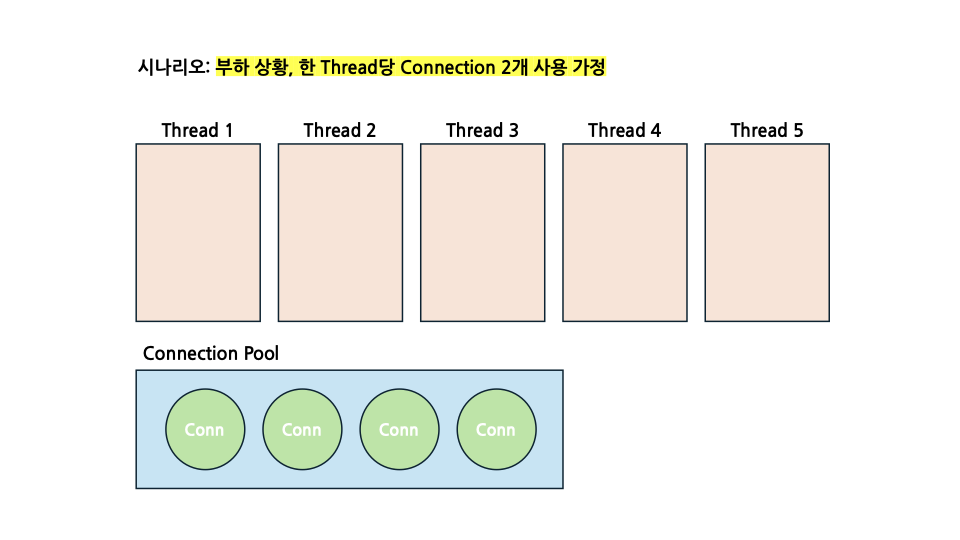
처음 상황은 위와 같은 그림에서 출발합니다. Thread가 5개, CP에 대기하고 있는 Connection은 4개인 것을 보실 수 있습니다.
그렇다면 이제 전체적으로 부하를 주어, 모든 Thread들이 동시에 작업을 시작했다고 가정해보겠습니다. 그렇다면 이때의 상황은 아래와 같습니다.
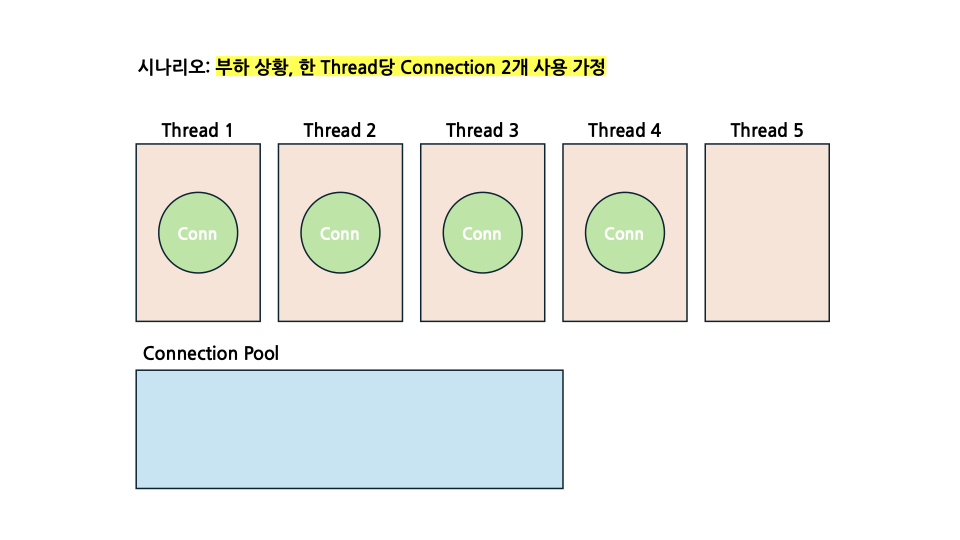
이때, 사용 가능한 Connection이 4개였으므로 Thread 5를 제외한 나머지 Thread들에서 트랜잭션을 시작합니다.
하지만 한 Thread당 Connection을 2개 사용하는 시나리오이기 때문에, 모든 Thread들이 각 태스크를 수행하기 위한 Connection이 부족한 상황이 됩니다.
그렇기 때문에 각 Thread들은 Connection을 얻기 위해서 HikariCP의 handOffQueue에서 대기하게 되고, 이는 곧 데드락으로 이어지게 되겠죠.
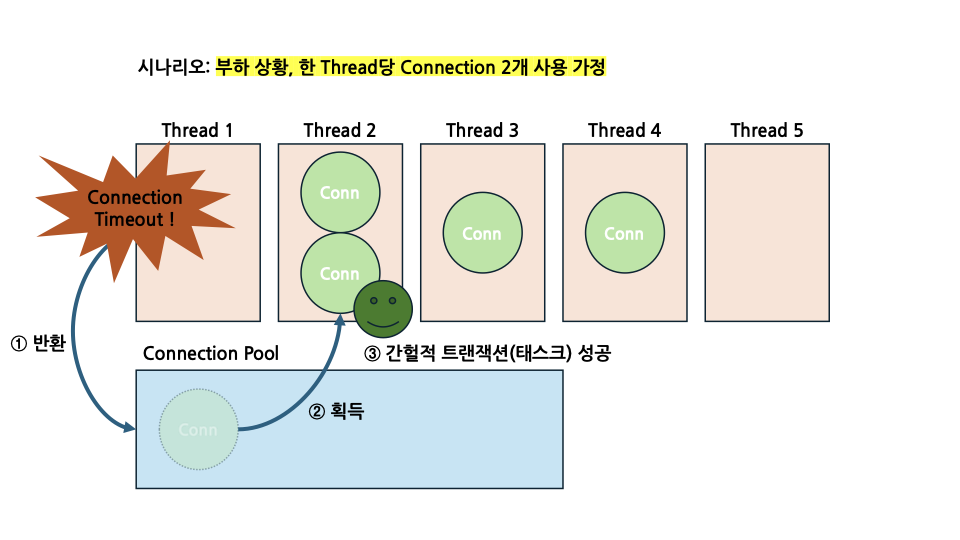
만약 Thread 1이 제일 먼저 Connection timeout 에러를 만나게 된다면, Thread 1에서 실행되던 트랜잭션이 롤백된 뒤 Connection을 CP에 반환하게 되는데, 간소한 차이로 다른 Thread에서 해당 Connection을 가져오게 된다면 간헐적으로 태스크가 성공하는 현상을 관찰할 수도 있습니다. 그림으로 보자면 아래와 같습니다.
HikariCP 데드락, 어떻게 피할 수 있을까?
지금까지 데드락 상황이 언제 발생하는지, 그리고 왜 발생하는지에 대해 다뤄보았습니다. 그렇다면 어떻게 하면 데드락을 피할 수 있을까요?
이에 대해서 HikariCP에 올라온 이슈 및 위키 글을 공유합니다.
Feature request: additional logging to debug connection pool deadlocks · Issue #442 · brettwooldridge/HikariCP
I ran into a problem caused by code in my application which would request and hold on to two connections simultaneously on the same thread. When testing the system under heavy load with 50 threads ...
github.com
About Pool Sizing
光 HikariCP・A solid, high-performance, JDBC connection pool at last. - brettwooldridge/HikariCP
github.com
HikariCP Wiki 에서는 아래의 공식을 제안하는데요.
pool size = Tn x (Cm - 1) + 1
- Tn = 최대 Thread 수
- Cm = 단일 Thread가 보유할 수 있는 최대 Connection 수
그렇다면 이제 공식을 토대로, 위에서 봤던 상황에서 CP 크기를 조절한 뒤 그림으로 상황을 다시 살펴보도록 하죠.
pool size = 5 x (2 - 1) + 1 = 6
- 최대 Thread 개수: 5개
- 한 Thread당 필요한 Connection의 수: 2개
- Thread가 전체적으로 일하고 있는 부하 상황
- HikariCP maximum pool size: 6개
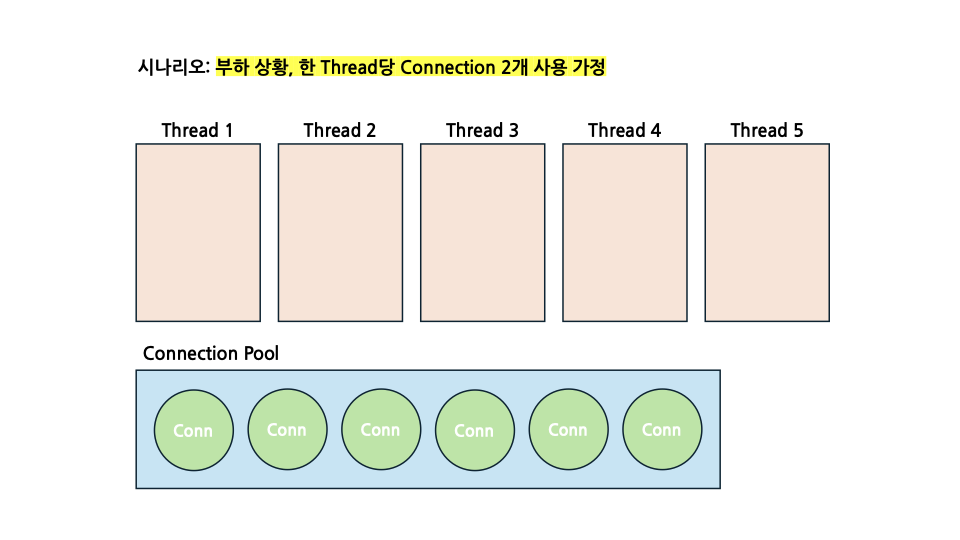
처음 상황부터 다시 보도록 하겠습니다. 부하 상황에서 모든 Thread를 가동하게 될 것이며, CP 크기는 전보다 2개 늘어난 6개가 되었습니다.

이번에는 각 Thread들 모두 Connection 1개를 획득하며 시작합니다. 여기서 주의깊게 봐야할 점은, 바로 CP에서 대기중인 1개의 Connection이 있다는 사실입니다. 그리고 저 1개의 Connection이 데드락을 해결해 줄 Key Connection이 됩니다.
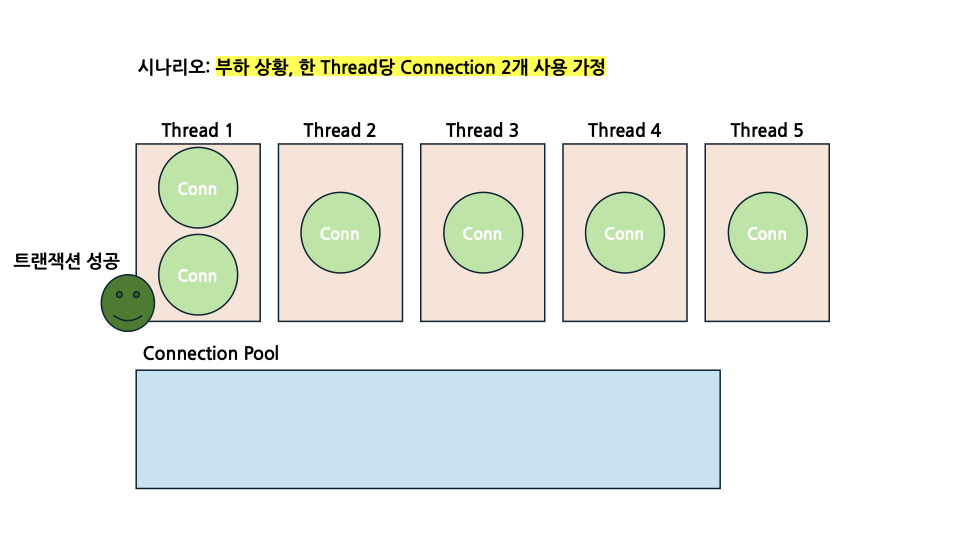
여유분의 Connection 한개가 Thread 1로 들어가게 되면서 모든 트랜잭션을 성공적으로 마치게 되었습니다. 그렇다면 이제 Thread 1이 점유하고 있던 Connection 2개는 CP로 반환이 될 것입니다.
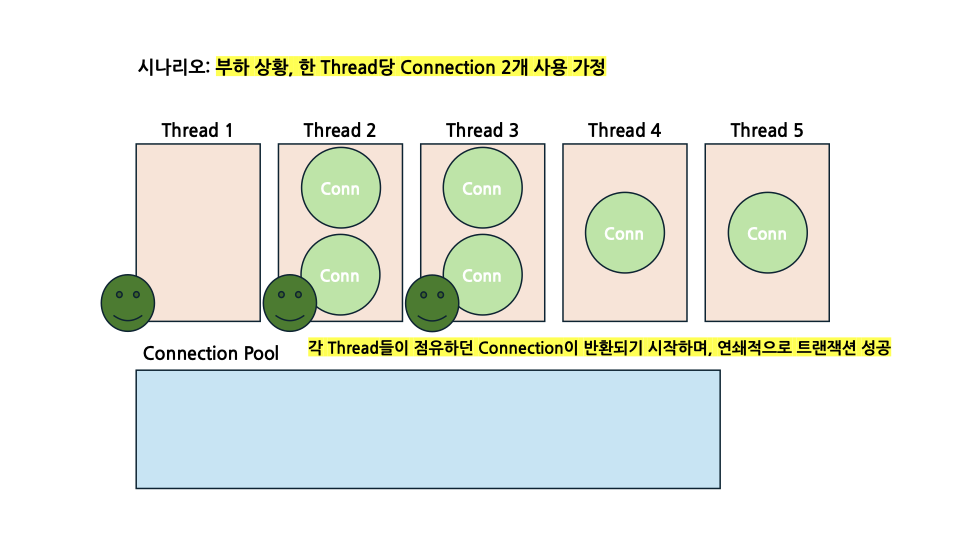
그 후, Connection을 기다리고 있던 각 Thread들이 Connection을 획득하기 시작하면서, 각 Thread들이 맡던 트랜잭션이 연쇄적으로 성공하게 되는 모습을 관찰할 수 있습니다.
pool size = Tn x (Cm - 1) + 1
아까의 공식을 다시 가져왔습니다. 그림을 통해 데드락이 해결되는 상황을 보니, 이 공식이 뜻하는 의미가 무엇인지 감이 오실 것 같습니다.
HikariCP 데드락은 어떠한 상황에서도 발생하면 안되기 때문에, pool size를 최대한 보수적으로 잡되, 그중에서도 최소한으로 잡아야 하는데요. 그러기 위해선 무엇이 최악의 상황인지 생각해보아야 합니다.
최악의 상황을 가정했을 때, 그것은 아마 모든 Thread들이 최대 Connection을 사용하는 시나리오 태스크를 진행할 때가 될 것입니다. 그중에서도 Tn * (Cm - 1) 개의 Connection들을 모든 Thread들이 골고루 나누어 획득하는 것이 가장 최악이 되겠죠.
그렇다면 위 경우에서, 데드락을 방지하기 위해서는 무엇이 가장 최선일까요?
그림에서도 보셨듯이, 여유분의 Connection을 1개 이상 가지고 있으면 됩니다. 그리고 그것이 곧 Key Connection이 될 것이고, 이는 공식에서 +1 으로 표현되어 있습니다.
결론
지금까지 HikariCP 데드락의 발생 상황, 그리고 이를 막기 위한 HikariCP pool size 산출 공식 해석까지 해봤습니다.
그렇지만 과연 이것이 최선일까요?
pool size = Tn x (Cm - 1) + 1
이 공식은 HikariCP 데드락을 피하기 위한 최소한의 pool size 입니다.
이 공식만을 사용해보면, Cm = 1인 경우에 pool size = 1이 되고, 즉 1개의 Connection을 가지고 모든 사용자의 요청을 처리할 수 있다는 뜻이기도 합니다.
다만 이는 매우 이론적인 공식으로, 실무에서 Connection 1개를 가지고 사용자 요청을 처리한다는 것은 매우 비효율적일 수 있는데요.
따라서, 실제로 공식을 적용할 때는 최소한의 pool size + α 가 되는 것이 좋습니다. 이때의 알파 값은 다양한 시나리오로부터 성능 테스트를 진행해보며 설정하는 것이 적절하겠죠.
(참고) 우아한형제들에서 확장시킨 공식은 아래와 같다고 합니다. (참고)
pool size = Tn x (Cm - 1) + (Tn / 2)
사실 HikariCP 의 pool size 튜닝을 할때 별 생각 없이 설정하곤 했었는데, 자칫하면 데드락이 발생하여 서비스 장애를 발생시킬 수 있다는 인사이트를 얻을 수 있었습니다.
본인이 개발하고 있는 서비스에서, 한 Thread가 잡을 수 있는 최대 Connection 수를 파악하여 HikariCP 성능을 적절히 튜닝하는 것이 좋겠습니다.
읽어주셔서 감사합니다!
댓글